Hypertext systems are emerging as a new class of complex information management systems. These systems allow people to create, annotate, link together, and share information from a variety of media such as text, graphics, audio, video, animation, and programs. Hypertext systems provide a non-sequential and entirely new method of accessing information unlike traditional information systems which are primarily sequential in nature. They provide flexible access to information by incorporating the notions of navigation, annotation, and tailored presentation [Bieber, 1993]. There are a number of research issues related to the design, development, and application of hypertext systems. This paper is a review of literature related to all these issues. This chapter is an introduction to hypertext, some existing systems, and some pioneers who have contributed to the definition and understanding of many aspects related to hypertext. Chapter 2 discusses issues related to hypertext implementation. Chapter 3 is on database requirements for hypertext systems. Chapter 4 discusses user interface issues and evaluation of hypertext. Chapter 5 is on information retrieval in hypertext systems. Chapter 6 discusses research efforts in the area of integrating hypertext with the work environment. Chapter 7 discusses some of the applications for which the hypertext paradigm is most suitable. Chapter 8 discusses a systematic approach to user interface design for a hyprtext system. It is an attempt to apply some of the ideas discussed in earlier chapters. Chapter 9 is a summary of all research issues and sets some directions for further work.
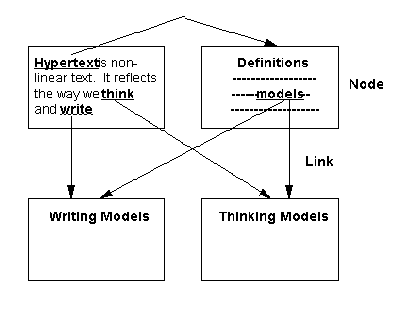
Hypertext has been defined as "an approach to information management in which data is stored in a network of nodes connected by links (Figure 1). Nodes can contain text, graphics, audio, video as well as source code or other forms of data." [Smith & Weiss, 1988]. Hypertext with multimedia is called "hypermedia". The promise of hypermedia[1] lies in its ability to produce large, complex, richly connected, and cross-referenced bodies of information.
In 1965, Nelson coined the word "hypertext" (non-linear text) and defined it as "a body of written or pictorial material interconnected in a complex way that it could not be conveniently represented on paper. It may contain summaries or maps of its contents and their interrelations; it may contain annotations, additions and footnotes from scholars who have examined it." [Nelson, 1965].
The original idea of hypertext was first put forth by Bush in July 1945. He described a device called "memex" in which an "individual stores his books, records and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory." [Bush, 1945]. He described the essential feature of memex as its ability to tie two items together.
The essential feature of hypertext, as defined in recent years, is the concept of machine-supported links (both within and between documents). It is this linking capability which allows a nonlinear organization of text.
Outside the academic world, due to the implementation of hypertext-like features in products such as MS Windows Help, information systems professionals are of the opinion that hypertext is just another user interface approach. However, hypertext is a hybrid that spans across traditional boundaries. It is a database method providing a novel way of directly accessing and managing data. It is also a representation scheme, a kind of semantic network, which mixes informal textual material with more formal and mechanized processes. It is an interface modality that features link icons or markers that can be arbitrarily embedded with the contents and can be used for navigational purposes [Conklin, 1987]. In short, a hypertext system is a database system which provides a totally different and unique method of accessing information. Whereas traditional databases have some structure around them, a hypertext database has no regular structure [Nielsen, 1990]. The user is free to explore and assimilate information in different ways.
Figure 1.1 Example of a Hypertext Document
A hypertext system is made of nodes (concepts) and links (relationships). A node usually represents a single concept or idea. It can contain text, graphics, animation, audio, video, images or programs. It can be typed (such as detail, proposition, collection, summary, observation, issue) thereby carrying semantic information [Rao & Turoff, 1990]. Nodes are connected to other nodes by links. The node from which a link originates is called the reference and the node at which a link ends is called the referent. They are also referred to as anchors. The contents of a node are displayed by activating links.
Links connect related concepts or nodes. They can be bidirectional thus facilitating backward traversals. Links can also be typed (such as specification link, elaboration link, membership link, opposition link and others) specifying the nature of relationship [Rao & Turoff, 1990]. Links can be either referential (for cross-referencing purposes) or hierarchical (showing parent-child relationships). Activation of link markers display nodes.
1. A Graphical User Interface, with the help of browsers and overview diagrams, helps the user to navigate through large amounts of information by activating links and reading the contents of nodes.
2. An authoring system with tools to create and manage nodes (of multiple media) and links.
3. Traditional information retrieval (IR) mechanisms such as keyword searches, author searches etc. There are also attempts to incorporate structure queries along with content queries - retrieving a part of the hypertext network based on some user-specified criteria.
4. A hypermedia engine to manage information about nodes and links.
5. A storage system which can be a filesystem or a knowledge base or a relational database management system or an object-oriented database management system.
The concept of hypertext has been around for a long time. The dictionary and the encyclopedia are very old forms of hypertext. These can be viewed as a network of textual nodes joined by referential links. The Talmud, with its heavy use of annotations and nested commentary, and Indian epics such as Ramayana and Mahabharata (stories branching off to other stories) are ancient prototypes of hypertext representation. We will review some of the well-known systems which have been implemented and widely studied by researchers in understanding various issues related to hypertext.
Bush is considered the "grandfather" of hypertext. He proposed a system called the "memex" as long ago as 1945 [Bush, 1945]. Though the system was never implemented, the concepts are still relevant to this day. Bush was concerned about the explosion of scientific literature which made it impossible even for specialists to follow developments in a field. He felt the need for a system that would help people find information more easily than was possible on paper.
The Memex would store information on microfilm which would be kept on the user's desk. The desk would contain many translucent screens on which several microfilms could be projected for convenient reading. The would also be a keyboard and sets of buttons and levers.
The Memex would have a scanner for user input of new material and it would also allow users to make handwritten marginal notes and comments. Apart from the conventional form of indexing, Bush proposed "associative indexing, the basic idea of which is a provision whereby any item may be caused at will to select immediately and automatically another. This is the essential feature of memex. The process of tying two items together is the important thing." [Bush, 1945].
As part of the Augment Project, primarily designed for office automation, Engelbart of SRI developed a system called NLS (oN Line System) which had hypertext-like features. This system was used to store all research papers, memos, and reports in a shared workspace that could be cross-referenced with each other [Engelbart, 1963]. In 1968, he demonstrated NLS as a collaborative system among people spread geographically.
For thirty two years now, Nelson has been working on his vision of a "docuverse" (document universe) where "everything should be available to everyone. Any user should be able to follow origins and links of material across boundaries of documents, servers, networks, and individual implementations. There should be a unified environment available to everyone providing access to this whole space." [Nelson, 1987].
Nelson designed Xanadu, a repository publishing system "intended to store a body of writings as an interconnected whole, with linkages, and to provide instantaneous access to any writings within that body." [Nelson, 1980]. This system has no concept of deletion. That is, it is a write-once system. Once something is published, it is for the entire world to see forever. As links are created by users, the original document remains the same except for the fact that a newer version is created which would have references to the original version(s). Since conventional file systems are not adequate to implement such a system, Project Xanadu has focused much of its attention on the re-design and re-implementation of file systems. This, in turn, required the creation of a whole new operating system incorporating a hypertext engine. The back-end for the system was scheduled to be released on Sun Workstations during 1992.
The Intermedia system, developed at Brown University's Institute for Research and Information Scholarship, is an integrated environment that allows different types of applications (word processors, editors, and other programs) to be linked together. It is a collection of tools that allows authors to link together the contents of text, timeline, graphics, 3-D models and video documents over a network of high-powered workstations [Meyrowitz, 1986]. The applications that exist within the Intermedia framework include a text editor (InterText), a graphics editor (InterDraw), a scanned image viewer (InterPix), a three-dimensional object viewer (InterSpect), and a timeline editor (InterVal).
The hypermedia functionality of the system is integrated into each application so that the creation and traversal of links can be intermixed with the creation and editing of documents. The system provides consistent, modeless, direct-manipulation applications. Strict conformance to user interface standards throughout the system makes it easy for the user to interact with all the applications in a similar manner.
Intermedia supports the concept of webs, composite entities that have many nodes and links between them. A link can belong to one or more webs. It provides three types of navigation tools: paths, maps, and scope lines. It supports shared and concurrent access to documents based on a system of access permissions. Intermedia has been used in presenting two courses online - English literature and biology [Yankelovich et al., 1988].
NoteCards is a hypermedia system for designers, authors, and researchers to analyze information, construct models, formulate arguments, and process ideas [Halasz, 1988]. Its basic framework is a semantic network composed of notecards connected by typed links. It provides users with tools for displaying, modifying, manipulating, and navigating through the network.
NoteCards contains four basic constructs: notecards, links, browsers, and fileboxes. Notecards contain information embedded in text, graphics, images, voice or other media. Links represent binary relationships between cards. Browsers display node-link diagrams of portions of the network. Fileboxes provide a mechanism to organize cards into topics or categories. NoteCards can be integrated with other systems running in the Lisp environment such as mail systems, databases, and expert systems.
Knowledge Management System (KMS), a descendant of ZOG, was developed at Carnegie Mellon University. It was designed to manage fairly large hypertext networks across local area networks. KMS is based on the basic unit called the frame. A frame can contain text, graphics, or images. Frames are connected to other frames via links. Links are of two types: tree items to represent hierarchical relationships and annotation items to represent referential relationships. In KMS, there is no distinction between browsing and authoring modes. Users can make changes to a frame or create links at any time and these changes are saved automatically [Acksyn et al., 1988].
KMS supports features such as aggregation, keyword searching, tailorability, collaboration, concurrency control, data integrity and security. It has been used for collaborative work, electronic publishing, project management, technical manuals and electronic mail.
HyperTies started as TIES (The Interactive Encyclopedia System) under the direction of Shneiderman at the University of Maryland's Human-Computer Interaction Laboratory. It provides authoring and browsing tools. A node may contain an entire article that may consist of several pages. Links are represented by highlighted words or embedded menus which can be activated using the keyboard or a touchscreen. Readers can preview links before actually traversing them. The user interface is relatively simple due to the original emphasis on museum information systems or kiosks. The commercial version is being used for a much wider spectrum of applications such as diagnostic problem solving, self-help manuals, browsers for libraries, and on-line help [Shneiderman, 1988].
Guide was developed by Peter Brown as a research project at the University of Canterbury, U.K. Later, it was commercially marketed by Office Workstations Limited both on the IBM PC and Apple Macintosh. It is the most popular commercial hypertext system. Text and graphics are integrated together in articles or documents. Guide supports four different kinds of links: replacement buttons, note buttons, reference buttons, and command buttons. Navigation through the replacement buttons initially provides a summary of the information and the degree of detail can be changed by the reader. Similar to KMS, Guide also does not distinguish between the author and the reader [Brown, 1987].
Textnet was designed and implemented by Trigg at the University of Maryland. It was developed to support the on-line scientific community in text creation, footnoting, annotating and critiquing. Textnet is a hypertext system based on a semantic network of nodes and labeled links. Nodes can be either primitive pieces of text called chunks or composite hierarchies called table of contents (tocs). There are two basic types of links: normal links and commentary links. In addition, there are about eighty different types of links with different functions [Trigg &Weiser, 1986].
Researchers at the University of North Carolina at Chapel Hill developed the Writing Environment (WE), a hypertext system based on a cognitive model of the communication process [Smith et al., 1987]. This model explains reading as the process of taking linear streams of text, comprehending it by structuring the concept hierarchically, and absorbing into long-term memory as a network. Writing is seen as a reverse process: A loosely structured network of internal ideas and external sources is first organized into an appropriate hierarchy or outline which is then translated into a linear stream of words, sentences, paragraphs, sections, and chapters [Smith et al., 1987].
WE was designed to support the process of writing. It contains two major view windows, one graphical and another hierarchical along with commands. The graphical windows allows the user to loosely structure their ideas in terms of nodes. As some conceptual structure begins to emerge, the writer can transfer the nodes into the hierarchy window which has specialized commands for tree operations. WE uses a relational database for the storage of nodes and links in the network. There are three other windows: an editor window, a query window, and a window to control system modes and the current working set of nodes. WE can be used both as a hypertext system as well as an authoring system with advanced graphical, direct manipulation structure editing capabilities [Conklin, 1987].
Other notable systems include: Hypertext Editing System (HES) and File Retrieval and Editing System (FRESS) from Brown University, MCC's Group Issue Based Information System (gIBIS).
Hypertext parallels human cognition and facilitates exploration. We think in nonlinear chunks which we try to associate with each other and build a network of concepts. When we read a book, we go back and forth a number of times to refer to previously read material, to make notes, and to jump to topics using the table of contents or the index. When we set out to write a document we first develop an outline of ideas. Then, we brainstorm, write down on paper, organize, revise, reorganize and repeat the cycle till we are satisfied with the outcome - a coherent document. In fact, we have been forced to adapt to traditional, linear text because of representation on paper.
In order to understand hypertext, it is very essential to understand how people read and write documents. Reading and writing models have been developed by cognitive psychologists that can be used to understand non-linear thinking by human beings [Rada, 1991], [Smith et al., 1987].
The theory of semiotics or the study of symbols shows that the understanding of knowledge takes place at four levels : lexical, syntactic, semantic and pragmatic [Rettig, 1992], [Rada, 1991]. At the lexical level, the user determines the definition for each word encountered. At the syntactic level, the subject, action and object of a sentence are determined. The meaning of a sentence is determined at the semantic level. The pragmatic interpretation of text depends on the integration of semantic meaning of text with the reader's knowledge of self and of the world.
While reading text, people proceed from a lexical level to the syntactic level, to the semantic and to the pragmatic levels in that order. All these levels interact continuously and they cannot be truly separated. The reader might have to have knowledge of the world in order to understand the meaning of a word. The correct syntactic and semantic interpretation of text may depend on the reader's knowledge of the world. Hence, though readers may proceed from words to sentences, to paragraphs and to the overall document, the progress is more forward and backward.
A mental representation of the meaning of text is then constructed which is in the form of propositions or relationships. While reading text, readers establish local coherence in short-term memory - small scale inferences from few small units of information (relationships between words, sentences and so on) [Thuring et al., 1991]. The reader makes preliminary hypotheses based on titles, words, propositions, and knowledge about the real world. A reading control system retrieves knowledge from the real world, present in long-term memory, in order to filter out information present in short-term memory. These hypotheses are refined as the reading of the text proceeds with the reading control system being invoked continuously. These propositions are combined into larger structures, also called global coherence [Thuring et al., 1991]. This hypothesized macroproposition or superstructure is used to understand the overall content of the text. The construction of a coherent mental representation has important consequences for navigation. In addition to generating forward references, we accumulate cues for backward navigation.
The reading control system uses the spreading activation model to access propositions or concepts. In semantic memory, each concept is connected to a number of other concepts. Activating one concept activates its adjacent concepts which in turn activate their adjacent concepts. Thus, activation spreads through the memory structure, determining what is to be added and what is to be removed from the interpretation of text. This process continues until further activation of adjacent propositions does not change the propositions used to interpret the text. That is, spreading activation decreases over time and semantic distance.
Writing is constrained by goal and audience. The author is guided by a goal but constrained by what the audience is prepared to accept. Different people approach writing in different ways. Some are good at making an outline first and then brainstroming. Some do the opposite. An expert author would always keep the reading model in mind so that the writing clearly reaches the target audience.
Writing involves the following three phases : exploring, organizing, and encoding [Rada, 1991]. In the Cognitive Framework for Written Communication (Figure 2), Smith et al. call these three phases: prewriting, organizing, and writing [Smith et al., 1987].
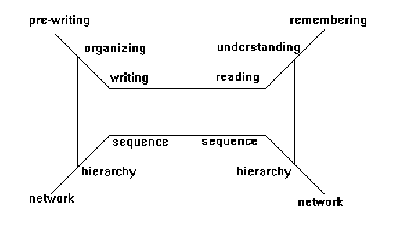
Figure 1.2 Cognitive Framework for Written Communication [Smith et al., 1987].
Exploring or pre-writing is the process of brainstorming and taking unstructured notes. The writer retrieves potential content from long-term memory or external sources, considers possible relations among ideas, groups related ideas and constructs small hierarchical structures. Thus, the product of exploration is a network or directed graph of ideas.
Organizing is the process of putting these notes or ideas in order, in the form of an outline or a hierarchy. This process involves abstract construction that involves perceiving subordinate/ superordinate relations, comparing abstractions, sequencing, proportion, and balance. Thus, the product of organization is a hierarchy of related concepts.
Encoding or writing is the final phase of completing the document. The primary task is translating the abstractions of content and the relations of a hierarchical structure into a sequence of words, sentences, paragraphs, sections, chapters, and illustrations. The structure of the encoded text is linear and represents a path through the hierarchy.
It is interesting to note that reading employs processes in the reverse order. That is, a linear sequence of words is transformed into a hierarchy which is later integrated into a network in long-term memory [Smith et al., 1987].
The writing model can be extended by considering unstructured and structured representation at each phase. Whereas an unstructured item is isolated, a structured item shows coherence. Exploring can be split into unstructured brainstorming followed by structured note-taking. Organizing can be classified as unstructured argumentation where relationships are established between ideas and structured organization of notes where notes are grouped together to make coherent sense. Encoding has an unstructured phase of linear planning which involves viewing groups of notes as sequences and a structured phase of drafting and revising in order to produce a final document (which is a linear sequence of notes).
Just as the reader of a linear document constructs a local and global mental representation of the document, the author of a linear document uses cues both at the local and at the global levels, dividing the document into chapters, sections, paragraphs, sentences, words etc. This facilitates comprehension and navigation [Thuring et al., 1991].
Thus, both reading and writing processes emphasize a lot on the non-linear nature of thinking, a natural process in human beings. Human cognition is essentially organized as a semantic network in which concepts are linked together by associations. Hypertext systems try to exploit this basic nature of cognition.
A hypertext is a database system which provides a unique and non-sequential method of accessing information. The essential features of hypertext are nodes and links. Nodes can contain text, graphics, audio, video, animation, and images while links connect nodes related in a certain manner. It is the linking capability which allows the non-linear organization of text. We have seen some of the pioneers in this field and some of the systems they built which have paved the way to understand better the theoretical and practical aspects of hypertext.
[Acksyn et al., 1988]. Acksyn, Robert M., McCracken, Douglas L., & Yoder, Elise, A. KMS: A Distributed Hypermedia System for Managing Knowledge in Organizations, CACM, July 1988.
[Bieber, 1993]. Bieber, Michael. Providing Information Systems with Full Hypermedia Functionality, Proceedings of the Twenty-Sixth Hawaii International Conference on System Sciences, 1993.
[Brown, 1987]. Brown, Peter J. Turning Ideas into Products: The Guide System, Hypertext '87 Proceedings, November 1987.
[Bush, 1945]. Bush, Vannevar. As We May Think, The Atlantic Monthly, July 1945.
[Conklin, 1987]. Conklin, Jeff. Hypertext: An Introduction and Survey, IEEE Computer, September 1987.
[Engelbart, 1963]. Engelbart, Douglas C. A Conceptual Framework for the Augmentation of Man's Intellect, Vistas In Information Handling, Volume 1, Spartan Books, Washnigton D.C., 1963.
[Halasz, 1988]. Halasz, Frank G., NoteCards: A Multimedia Idea Processing Environment, Interactive Multimedia edited by Ambron, Sueann and Hooper, Kristina, Microsoft Press, 1988.
[Meyrowitz, 1986]. Meyrowitz, Norman K., Intermedia: The Architecture and Construction of an Object-Oriented Hypermedia System and Applications Framework, OOPSLA '86 Proceedings.
[Nelson, 1965]. Nelson, Ted. A File Structure for the Complex, The Changing and The Indeterminate, ACM 20th National Conference, 1965.
[Nelson, 1980]. Nelson, Ted. Replacing the Printed Word: A Complete Literary System, Information Processing '80, 1980.
[Nelson, 1987]. Nelson, Ted. All for One and One for All, Hypertext '87 Proceedings, November 1987.
[Nielsen, 1990]. Nielsen, Jakob. Hypertext/Hypermedia. Academic Press, 1990.
[Rada, 1991]. Rada, Roy. Hypertext: From Text to Expertext, McGraw Hill Publishers, 1991.
[Rao & Turoff]. Rao, Usha & Turoff, Murray. Hypertext Functionality: A Theoretical Framework, International Journal of Human-Computer Interaction, 1990.
[Rettig, 1992].
[Shneiderman, 1988]. Shneiderman, Ben. User Interface Design for the HyperTies Electronic Encyclopedia, Hypertext '87 Proceedings, November 1987.
[Smith & Weiss, 1988]. Smith, John & Weiss, Stephen. An Overview of Hypertext, CACM, July 1988.
[Smith et al., 1987]. Smith, John B., Weiss, Stephen F., and Ferguson, Gordon J. A Hypertext Writing Environment and Its Cognitive Basis, Proceedings of Hypertext '87, ACM Press, 1987.
[Thuring et al., 1991]. Thuring, Manfred, Haake, Jorg M., and Hannemann, Jorg. Hypertext '91 Proceedings, 1991.
[Trigg & Weiser, 1986]. Trigg, Randall & Weiser, M. TEXTNET: A Network Based Approach to Text Handling, ACM Transactions on Office Information Systems, January 1986.
[Yankelovich et al., 1988]. Yankelovich, Nicole, Haan, Bernard J., Meyrowitz, Norman K., Drucker, Steven M., Intermedia: The Concept and the Construction of a Seamless Information Environment, IEEE Computer, January 1988.